Pre-meeting
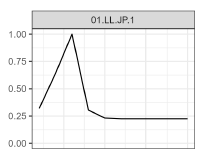
Following SC20 and prior to the modeling meeting, SPC continued development on the stock assessment model to try and improve the fit to the size composition data. These additional investigations focused on how selectivity was defined in the model. In the 2024 stock assessment (Castillo-Jordan et al., 2024), cubic-splines were used to define flexible selectivity curves as a function of age noting that implementation in restricts placement of nodes to age class values. Since the 2024 assessment assumed 10 annual age classes this placed a severe constraint on the shape of the selectivity curve (Figure 1), particularly at the youngest ages when growth was assumed to be quite rapid. A new model mfcl-1979-20p3 (Figure 2) was reparametrized in using quarterly age in order to provide greater resolution in age-specific selectivity at the youngest sizes (Figure 3). The new quarterly age model also included a separate index for each of the four quarters which shared a stationary catchability, and selectivity curve. Additionally, time-varying observation error for each index was not activated and instead assumed a \(\sigma = 0.17\).
While this new model mfcl-1979-20p3 had the desired effect of improving the resolution of selectivity and fits to size composition data, it introduced a new problem into the population dynamics. are not known to spawn year-round like tropical tunas, but rather have a restricted spawning season in the late austral spring and early austral summer where they form multiple discrete spawning aggregations (Kopf et al., 2012). However, in it is difficult to restrict recruitment in a quarterly model to occur in a single quarter of the calendar year. An orthogonal polynomial parametrization for recruitment was applied to restrict recruitment to the first quarter of the calendar year (following spawning in the early austral summer), however the model still introduced recruits into the model in all quarters of the year (Figure 4).
January 2025 meeting
Model investigations during the January 2025 stock assessment modeling meeting used the mfcl-1979-20p3 model provided by SPC as a starting point. A table of key model convergence and fit metrics is provided in Table 1.
Model configuration files, output, and analytic code are available on GitHub : https://n-ducharmebarth-noaa.github.io/2025-swpo-mls-meeting/.
Transition to Stock Synthesis
Discussions in the lead up to the January 2025 meeting identified that switching the modeling framework from to Stock Synthesis (Methot & Wetzel, 2013) could help resolve some of the issues identified by SC20 that the mfcl-1979-20p3 model sought to address without compromising key population dynamics assumptions (e.g., annual population dynamics and recruitment). One of the key benefits to is that it can model selectivity as a function of length and/or age. This improves the resolution of the selectivity curve and fit to the size data while maintaining annual population dynamics.
An initial model 01-mls-base-1979 was configured to approximate the available mfcl-1979-20p3 model. 01-mls-base-1979 implements a single-sex model spanning 1979-2023 with annual age-structure and quarterly population and fishing dynamics. An early recruitment period from 1969-1978 was used to set-up the initial population age structure, and the initial level of fishing mortality (initF) was fixed to match the mfcl-1979-20p3. Fishery definitions and selectivity groupings were maintained with selectivity defined as a function of length assuming a double-normal functional form. All length and weight composition were reformatted using the bin structure. To initialize the model, the input effective sample sizes for the weight and length composition matched the sum of the input observations from the mfcl-1979-20p3 for each quarterly fishing instance. Rather than use the four quarterly indices, a single quarterly index corresponding to quarter 4 was used in the Stock Synthesis model. Quarter 4 was selected as this was the one most likely to represent changes in the spawning component of the population given the temporal reproductive dynamics described by Kopf et al. (2012). The time-varying observation error specified, but not used, in the mfcl-1979-20p3 model were applied in this case.
Biological parameters were converted from the mfcl-1979-20p3 model. Growth followed a von Bertalanffy function characterized by explicit parameter values: \(L_1\) = 88.38 cm at age 0.25 years, \(L_2\) = 210.96 cm at age 10 years, and \(k\) = 0.84, with CV structure following a length-at-age pattern. Reproduction dynamics incorporated a Beverton-Holt stock-recruitment relationship with steepness fixed at 0.8 and recruitment variance (\(\sigma_R\)) set to 0.2, while the maturity ogive was logistically parameterized with length at 50% maturity at 181.21 cm and a slope parameter of -0.20.
Initial results from the 01-mls-base-1979 (or 25-mls-base-1979-corrected) models did not show particularly close agreement with the mfcl-1979-20p3 temporal dynamics or spawning biomass scale, however estimates of population numbers were more comparable (Figure 5). However, this model was not expected to show good agreement as it assumed naïve sample sizes for the size composition data and the difference in treatment of observation error for the index. Most importantly, the model ran and could form the basis for further refinements to model structure in order to improve the fit to various data components.
Early refinements
Following the successful run of the 01-mls-base-1979 model, a pair of follow-on models were developed in a stepwise manner to address model fit and statistical treatment of data inputs. These modifications resulted in the 02-mls-ss3-1979 and 03-chg-selex-1979 model configurations.
The 02-mls-ss3-1979 modifications focused on improving model performance while preserving the fundamental assumptions of the baseline model. Selectivity parameterization was modified through three key adjustments: (1) converting fixed end logit parameters to estimated parameters for fleets using double-normal selectivity; (2) fixing top logit parameters enforce dome-shaped selection where empirically supported; and (3) replacing the New Zealand recreational fishery’s double-normal selectivity with a simpler logistic function. These changes provided greater flexibility in fitting length composition data while maintaining biologically plausible selection patterns. Statistical treatment of composition data was refined by increasing the minimum tail compression value to 1e-02 and implementing fleet-specific effective sample size adjustments (down-weighting factors of 0.03-0.10) to match the level of down-weighting seen in the mfcl-1979-20p3 model. Additionally, the CPUE index error structure was augmented with an observation error component (0.191) derived from loess smoother residual analysis. These modifications collectively addressed potential over-dispersion in composition data and explicitly accounted for potential un-modeled observation error in the standardized index.
Following the implementation of the 02-mls-ss3-1979 model, further adjustments focusing specifically on selectivity were explored in the 03-chg-selex-1979 model. For Fishery 2 (Japanese longline in sub-region 2), Fishery 9 (Australian recreational), Fishery 12 (aggregated longline in sub-region 2), and the standardized abundance index (Fleet 15), the top logit parameters were changed from fixed values to estimated parameters. Concurrently, for these same fleets, the end logit parameters were reverted from estimated parameters to fixed values (-999) to maintain parameter identifiability. This adjustment effectively allowed the peak of the selectivity curve to be estimated while allowing its right-hand tail behavior to decline gradually.
Modifiying selectivity modeling and size composition data weighting in the 02-mls-ss3-1979 model improved the fit to the index (Figure 6) and resulted in somewhat more reasonable selectivity curves. However, issues remained, noticeably for Fleets 2 (Japanese LL; sub-region 2) and 15 (Index). Further tweaking the selectivity in model 03-chg-selex-1979 degraded the fit to the index slightly but resolved some of the existing selectivity issues and generally improved fit to length (Figure 8) and weight (Figure 9) data.
Reverting model start year to 1952
One of the issues raised at SC20 was the lack of ability of the diagnostic-2024 model to estimate initial conditions in 1979, rather than begin the model at an unfished equilibrium in 1952 as was done in the diagnostic-2019 model. Initial conditions in 1979 in the diagnostic-2024 model were tuned (assuming initial total mortality \(Z\) to be \(1.7 \times M\), natural mortality) to match the level of depletion (\(\sim 0.35\)) seen in 1979 from the diagnostic-2019 model. Rationale given for changing the start year to 1979 in the diagnostic-2024 model was to include vessel random effect in the standardized index, and to avoid the issue of implausibly high estimated recruitments in the early years that arose after switching to the updated growth curve.
Following the switch to , a new model beginning in 1952 04-start-1952 was developed from the 03-chg-selex-1979 model to address the initial conditions issue raised with the diagnostic-2024 model, and to see if the alternative selectivity formulation as length-based alleviated the issue of implausibly high estimated recruitments in the early years. The extended model incorporates historical catch data from 1952-1978 extracted from the diagnostic-2019 model. The only size composition data that was included was the New Zealand recreational (Fleet 10) weight composition data. Given that this fishery assumed a logistic selectivity shape, observed declines in average weight could provide information about adult abundance trend and total mortality \(Z\) during the years prior to the start of the standardized index. Treatment of the initial condition (e.g., no longer including steepness effects in the initial equilibrium calculations and removal of initF parameter) was also changed to accommodate starting at an unfished condition. Lastly, the recruitment dynamics were reconfigured to accommodate the longer time series. Specifically, the recruitment deviation framework was expanded to span 1952-2021 (recruitment in the last year of the model was not estimated), with early recruitment deviations beginning in 1942 and bias adjustment parameters recalibrated for the extended time series.
Switching back to a 1952 start from an unfished condition in the 04-start-1952 model resulted in dynamics that were much similar to the diagnostic-2019 model (Figure 10), especially in terms of more recent estimates of spawning biomass scale and depletion. The change in how recruitment is modeled between and with the use of the early recruitment period and recruitment bias-adjustment ramp eliminates the large spike in recruitment seen in the diagnostic-2019 model and overall recruitment variability in the 04-start-1952 is moderated relative to the two models. Changing to the 04-start-1952 model did degrade fit to the index in later years (Figure 11).
Excluding size composition data
The next phase of developments considered the effect of removing size composition data from the model that were believed to be unsuitable for use in the model for either data quality, or sampling concerns. Prior to the meeting start, the SPC spent considerable time reviewing the size composition data for each fishery and provided guidance (P. Hamer, pers. comm.) on which data should be excluded. Based on this information, two additional models 05-exclude-bad-comp and 06-exclude-more-comp were sequentially developed from 04-start-1952 to remove un-representative data, minimize data conflicts, and improve the fit to the remaining data (index and size composition). Note that these exclusions were largely exploratory and does not necessarily reflect final decisions on the inclusion/exclusion of data for a proposed 2025 stock assessment model. The cumulative changes leading to the 06-exclude-more-comp are described below.
Length composition changes
- Fleet 1 (JP LL; sub-region 1): Eliminated all length composition due to small sample sizes and temporal patchiness.
- Fleet 2 (JP LL; sub-region 2): Eliminated all length compositions due to conflict with corresponding weight data and temporal patchiness.
- Fleet 6 & 7 (AU LL): Excluded all length compositions due to internal conflict with corresponding weight composition data and temporal patchiness relative to more comprehensive weight data.
- Fleet 8 (NZ LL): Removed all length compositions based on inadequate sample sizes and temporal patchiness.
- Fleet 11 (Aggregate LL; sub-region 1): Targeted removal of 2006-2014 length composition data to exclude TWDW data which may have data quality issues.
- Fleet 12 (Aggregate LL; sub-region 2): Eliminated all length compositions. Mixed-flag fishery compositions are spatiotemporally patchy and may fail to representatively capture aggregate fishery dynamics despite potentially having adequate sampling of individual fleet components.
- Fleet 13 (Aggregate LL; sub-region 3): Same as for Fleet 12.
- Fleet 14 (Aggregate LL; sub-region 4): Removed pre-2006 data that demonstrated anomalously small size observations.
- Fleet 15 (Index): Complete removal of length composition due to conflict with weight composition data and evidence of less comprehensive temporal sampling compared to the weight data.
Weight composition changes
- Fleet 1 (JP longline; sub-region 1): Removed all weight composition data due to small sample sizes and temporal inconsistencies
- Fleet 2 (JP longline; sub-region 2): Specifically removed 1979 weight composition data due to apparent sampling anomalies
- Fleet 10 (NZ recreational): Excluded post-1988 weight composition due to management-induced changes in size selectivity (encouraging non-retention of small individuals) that may bias post-1988 samples
Selectivity changes
The selectivity grouping for Fleet 12 was shared with Fleet 2, given the removal of all composition data for Fleet 12 (see Table 2 for updated fishery definitions).
Fits to the index (Figure 12) as well as the remaining composition data (length: Figure 13 and weight: Figure 14) were predictably improved when un-representative and conflicting composition data were removed.
Catch uncertainty
One of the concerns raised during development of the diagnostic-2024 model was the influence of large catch event by the Fleet 2 (Japanese LL; sub-region 2) in 1954. This was also a concern in the diagnostic-2019 model, and sensitivity to the starting year was explored in that previous assessment to exclude that large catch observation (Ducharme-Barth et al., 2019). A different approach was taken in the current explorations, and the 07-catch-uncertainty was developed to account for potential uncertainty in the historical catch.
The 07-catch-uncertainty model built on the 06-exclude-more-comp model and bifurcated Fleet 2 (Japanese LL; sub-region 2) into two temporal components. This created a distinct fleet (F15_LL.JP.2_early) for pre-1979 data while maintaining the original fleet for more recent observations. Selectivity was shared between the two fleets. However, moving to F_Method = 4 allowed some fleets (Fleets 1 - 14) to stay defined as catch-conditioned, where fishing mortality is calculated to fit the catch exactly, and have Fleet 15 estimate the fishing mortality (F) needed to fit to the catch with observation error. This structural modification also enabled differential parameterization of catch uncertainty, with higher standard errors (SE=0.2) assigned to quarters with higher catch observations (quarters 3-4) and lower uncertainty (SE=0.05) to quarters with lower catch observations (quarters 1-2). Additionally, the catch-conditioned F values for Fleet 15 were used as initial values in the estimation of F. The index fishery stayed the same but became Fleet 16. Parameterizing the model in this way allowed for potential uncertainty in historical catch to be propagated in model estimates in a computationally efficient manner.
Adding in catch uncertainty (Figure 15) did not greatly change time series estimates of key stock assessment outputs (Figure 16) though it did appear to improve fits to the index (Figure 17).
Treatment of growth
Using the 07-catch-uncertainty as a baseline, a number of additional models were developed to explore alternative ways of dealing with growth. Growth was a major source of discussion as some of the issues identified in development of the diagnostic-2024 model became more pronounced after switching to a new growth curve provided by Farley et al. (2021), with the new curve showing exceptionally rapid growth through the first year of life. This was flagged as a concern given the opportunistic nature of sampling for the otoliths from longline landed individuals which has reduced selectivity at smaller sizes and would only capture the most rapid growing individuals in the youngest age classes. In an effort to improve model fits and alleviate any potential mis-specification in the growth curve, two classes of models were developed.
Models 08-relax-growth and 09-relax-growth-v2 attempted to improve the fit by defining variability in growth using CV as a function of length at age, rather than as a standard deviation, and setting the CV for yound and old fish to be 0.15. In the 08-relax-growth model \(L_1\) was set to 59.9 cm and assumed an age at \(L_1\) of 0, while in the 09-relax-growth-v2 model \(L_1\) was set to 88.3822 cm and assumed an age at \(L_1\) of 0.25. These models ended up describing functionally identical growth curves, though it was initially unclear from the documentation that this would be the case.
Models 10-CAAL, 11-CAAL-no-ageerr, 12-CAAL-old-growth-SD, and 13-CAAL-noAgeerr-OGsd all attempted to improve fit by estimating growth internally using the aging data from the Farley et al. (2021) study as conditional age-at-length data. Data were associated with the appropriate fleet definition based on sampling location and flag of vessel sampled from. Though the aging data recorded decimal age, age was entered in the model as the nearest model age less than or equal to the decimal age. Given that model ages were annual, this meant integer age values. For all models \(L_1\), \(L_2\) and \(k\) were freely estimated.
Models 10-CAAL and 11-CAAL-no-ageerr both defined variability in growth using CV as a function of length at age in the same way as models 08-relax-growth and 09-relax-growth-v2. Model 10-CAAL included an aging error matrix with standard deviations of aging error standard deviation ranging from \(\sigma_{Age} = 0.35\) at age 0 to \(\sigma_{Age} = 2\) at age 10. This was done to account for both actual aging error and for converting from decimal age to integer age to match the model structure.
Models 12-CAAL-old-growth-SD and 13-CAAL-noAgeerr-OGsd both defined variability in growth using standard deviation as a function of length at age in the same way as model 07-catch-uncertainty, where the standard deviations at the youngest and oldest model ages were \(\sim10\). Model 12-CAAL-old-growth-SD included the same aging error matrix as 10-CAAL while model 13-CAAL-noAgeerr-OGsd did not.
Estimation of growth internally using conditionaly age-at-length data and size composition slowed growth (lower \(k\)) and increased \(L_2\) (Figure 18), which had a small effect on recent time-series estimates (Figure 19). It also improved fits to the index (Figure 20), length composition (Figure 21) and weight composition (Figure 22) overall though some fisheries noticeably deteriorated (e.g., the S01_INDEX weight composition data). We note that although the variability in length at age between the formulations using CV vs. standard deviation were approximately the same, the models showed greater stability when variability in growth was defined using a standard deviation as a function of length at age.
Additional investigations
The 12-CAAL-old-growth-SD model emerged from this process as a reasonable candidate from which a numer of additional investigations were attempted. These are briefly described below.
14-CAAL-target-earlyF: Built off 13-CAAL-noAgeerr-OGsd to implement a targeted approach to historical catch uncertainty by specifically isolating Japanese longline catches from 1954-1978 with values greater than 1 into a separate fleet (Fleet 15) with elevated uncertainty (0.2), while maintaining lower uncertainty (0.01) for all other fleet 2 catches. This refinement built directly upon 13-CAAL-noAgeerr-OGsd but applied a more focused treatment of uncertainty to historical catch. This had negligible impacts on estimated quantities.15-CAAL-qtrAge: Attempted to input the conditional age-at-length data as quarterly ages but this was unsuccessful.16-CAAL-rm-spike: This model modified 12-CAAL-old-growth-SD to remove the index observation in 1998 to see if attempting to fit this high point was driving the misfit to the index seen in 2000 - 2002. Assessment results with that observation removed showed little meaningful difference with the 12-CAAL-old-growth-SD model results indicating that it is not likely to be the source of the index misfit.17-CAAL-noAU-ASPM: This model modified 12-CAAL-old-growth-SD to keep the selectivity values for Fleet 6 (Australian LL; sub-region 2) fixed at the values estimated from model 12-CAAL-old-growth-SD and removed all of the Fleet 6 weight composition data from the likelihood to see if the weight composition data from this fishery was driving the misfit to the index seen in 2000 - 2002. Fit to the index was substantially improved without the inclusion of this data indicating that conflict with this data source is likely the cause of the misfit.18-CAAL-cUnc-cv40: Built directly off of 12-CAAL-old-growth-SD to evaluate assessment sensitivity to increased historical catch uncertainty by doubling the standard error values for Fleet 15 (early Japanese longline) from 0.2 to 0.4 (seasons 3-4) and from 0.05 to 0.1 (seasons 1-2). This targeted modification tested the sensitivity of model results to assumptions on historical variability in catch. This had a slight impact to biomass estimates in the early model period showing some sensitivity to this assumption.19-CAAL-1979: This model attempted to merge 03-chg-selex-1979 with 12-CAAL-old-growth-SD by begining the model in 1979 with fixed initF, excluding all of the non-representative size composition data, and including the estimation of growth using conditional age-at-length data with an aging error matrix. This model ran but produced biomass estimates that were almost double 03-chg-selex-1979.20-CAAL-1979-estInitF: Structurally identical to 19-CAAL-1979 except that initF is estimated. This model was unsuccesful as biomass estimates became unrealistically large.21-CAAL-NZrecwtQtr: Built off 12-CAAL-old-growth-SD and re-allocated the New Zealand recreational fishery weight composition data from annual observations in the first quarter of the calendar year to the quarterly periods in which they were observed. This is a more appropriate treatment of the data, but did not result in percievable differences in model estimates.22-1979-estInitF-v2: Built off 03-chg-selex-1979 and successfully estimated initF. Time series estimates of recruitment, depletion, and spawning biomass appeared similar to the 2024-diagnostic model.23-CAAL-2sex: This model implemented a 2-sex version of the 12-CAAL-old-growth-SD model and estimated sex-specific growth as a proof of concept model. Other biological parameters were assumed to be equivalent between sexes for the sake of this example model. The model ran and produced similar estimates to the single-sex model however with a higher than desired maximum gradient indicating that estimating sex-specific growth internal to the model may be ambitious.24-CAAL-Richards: This model implemented a Richards growth model version of the 12-CAAL-old-growth-SD model. Growth was very slightly more rapid with the estimation of a fourth growth parameter but stock status estimates were largely unchanged.
The key take-aways from these investigations were:
- the misfit to the index seen in 2000 - 2002 is driven by conflict with the Fleet 6 (Australian LL; sub-region 2) weight frequency data which suggests an increasing trend in mean size over the period 1998 - 2002, rather than a decline as seen in the index (Figure 23),
- a two sex model is technically feasible though estimation of sex-specific growth parameters may not be (Figure 24 & Figure 25),
- growth estimates are slightly sensitive to the functional form used, either von Bertalanffy or Richards (Figure 26),
- re-allocating New Zealand recreational fishing weight composition data to quarters is more correct but doesn’t impact results (Figure 27) and,
- model estimates are slightly sensitive to the choice of uncertainty given to the early period catch (Figure 28 & Figure 29).
Single-sex model development could progress using either 12-CAAL-old-growth-SD or 21-CAAL-NZrecwtQtr as a starting point. Two-sex model development could progress using 23-CAAL-2sex as a starting point noting that may need to be modified to match the quarterly treatment of New Zealand recreational fishery weight composition data used in 21-CAAL-NZrecwtQtr.